How many of you think having advanced search capabilities for websites would be nice? Advanced search as in, for example – searching for content inside a word file or pdf file? Or may be search results showing up as soon as you start typing? Or may be showing search suggestions like Google but in the search box of your own websites?
Why would anyone need such a search?
Your customers or your website visitors would have the ability to search and find the information they need accurately and fast.
Some researchers have shown most users have a attention span of 7 – 8 seconds before going to the next website. You would have spent a lot of effort on Search Engine Optimization to get people to know your website. Now, if people can find what they are looking for quickly and accurately wouldn’t that help? May be the prospective visitor ends up being a sales lead and a customer.
This is the concept for an upcoming product. The product was internally code named as WebSearch but then wanted a unique name for the product and renamed as WebVeta. Veta in my mother tongue language Telugu means Hunt. In other words hunt for your files / content.
If this concept seems appealing and if you think you might have a need, please do contact.
Few example scenarios:
Scenario – 1: Let’s say you have a multi-nation presence and all of your company addresses are mentioned somewhere in the website. And someone from Australia wanted to find your U.S.A office address or phone number – how about they start typing “U.S.A pho” and the U.S.A phone number shows up?
Scenario – 2: Let’s say you have a global corporate website, a u.k based website, a U.S.A based website with URL’s between the 3 websites. But search inside each website shows results for only that website. What if the 3 websites can show consistent search results including advanced search capabilities across the three websites? i.e irrespective of on which website, your customer is can find information from across your global corporate websites.
Most of you know I like sharing my knowledge. Here are some simple but very useful DOM manipulation functions in Javascript.
As part of development for WebSearch, I wanted leaner Javascript and for some part of the development, I am using direct Javascript rather than libraries such as jQuery. jQuery has these functionality and allows easier development. My situation and necessity are a bit different.
var ele = document.getElementById("elementid");
// for getting a reference to an existing element in the DOM
var dv = document.createElement("div");
// for creating a in-memory element.
parentEle.appendChild(childEle);
// for adding an element as a child element of another element
ele.id = "elementId";
// Setting id of element
ele.classList.add("cssClass");
ele.classList.remove("cssClass");
// Adding and removing css classes
ele.innerText = "Text";
ele.innerHTML = "<>...M/>";
// Setting text and innerHTML
// caution with innerHTML - don't inject unsafe/unvalidated markup
ele.addEventListener("event", (ev) => {
// Anonymous function
});
// Handle events such as click etc...
ele.addEventListener("event", fnEventHandler);
// Handle events by using a function - fnEventHandler
There are various solutions for collecting, storing and viewing metrics. This blog post is specifically about the following list of software:
CollectD – For collecting system metrics
Carbon-Relay-ng – Like a server but forwards the metrics into Graphite
Hosted Graphite at Grafana.com – The backend that stores the metrics
Grafana – For viewing metrics
Grafana for alerts
Collectd
Collectd is a very light-weight, low memory, low CPU usage Linux tool that runs as a service and can collect various system related metrics. Collectd is very extensible and has several plugins. Some of the plugins, I like and have used are:
Apache web server – Gathers Apache related stats
ConnTrack – Number of connections in Linux connection tracking table
ContextSwitch – Number of context switches
CPU
DNS
IP-Tables
Load
MySQL
Processes
tcpconns
users
vmem
My favorite output plugins and some I am familiar with are:
CSV
Write Graphite
gRPC
Carbon-relay-ng
This is not necessarily my favorite, because little heavy on system resources 🙁
Now host Carbon-relay-ng on one of the servers, Install Collectd on the servers that need to ingest metrics. Use Collectd’s Write_Graphite for ingesting metrics into Carbon-relay-ng. Configure Carbon-relay-ng to ingest metrics into hosted Graphite on Grafana.com.
For ingesting any code-based metrics use ahd.Graphite.
var client = new CarbonClient("example.com");
var datapoints = new[]
{
new Datapoint("data.server1.cpuUsage", 10, DateTime.Now),
new Datapoint("data.server2.cpuUsage", 15, DateTime.Now),
new Datapoint("data.server3.cpuUsage", 20, DateTime.Now),
};
await client.SendAsync(datapoints);
//Sample code from - https://github.com/ahdde/graphite.net
I would say instead of instantiating too many instances, use either singleton or use a very small pool of instances.
I have promised to semi-open-source some code from my upcoming project – Alerts in the anouncements blog. Anyone with some programming knowledge, can implement such a solution by following this blog. This would be implemented slowly because I am planning to get normal 9 – 5 job, instead of joining or participating in the r&aw dawgs human rights violation, game of loans, game of identity distortion (in this case, I am the victim and their offer, if I participate – identity distortion of some American – sorry, I am not a psycho)
Moreover, for at least 6 – 12 months, the project would be offered completely free of charge for some companies / individuals who see a need and can provide feedback.
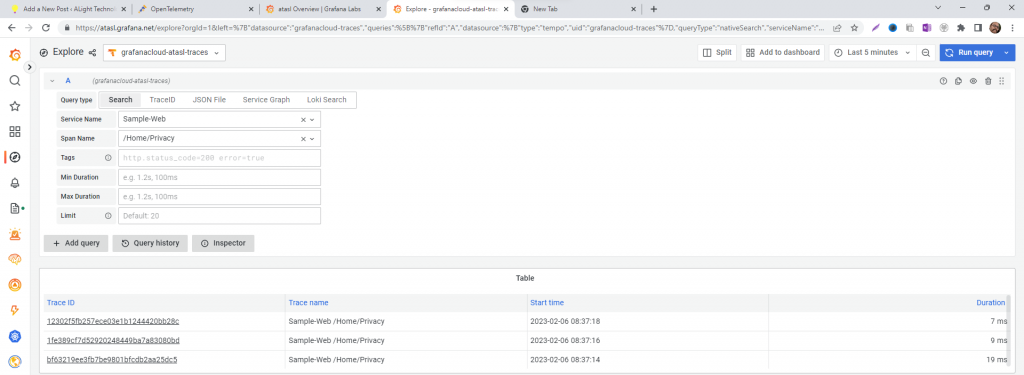
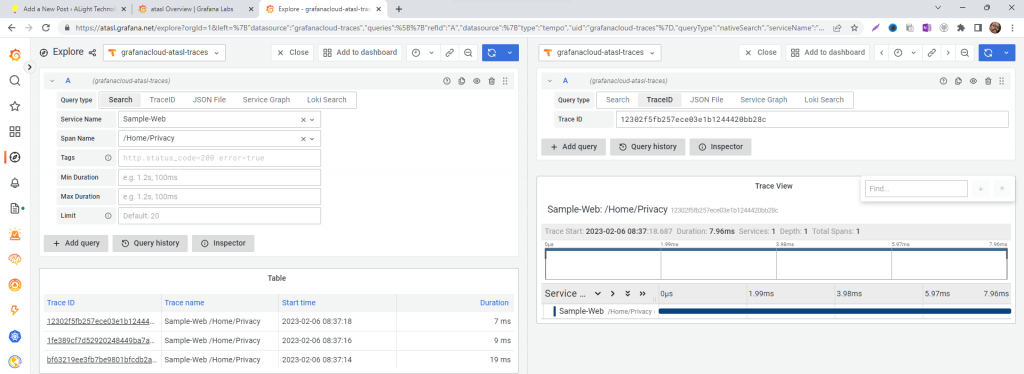
OpenTelemetry is pretty much like logs and metrics with distinguishable TraceId’s.
Yesterday and this morning I have experimented with OpenTelemetry in a sample ASP.Net MVC application.
The Primary components are:
A host for Tempo – using Grafana hosted Tempo – https://www.grafana.com. Grafana has a very generous 100GB traces per month in the free tier.
Grafana Agent – As of now, I have used Grafana Agent on Windows laptop, have not configured on Linux production servers yet. Grafana Agent can be downloaded from here. Click on the releases in the right side and choose the Operating System. Here is the link for v0.31.0.
Add the following pre-release dll’s to your ASP.Net MVC application.
“OnLINE Erra, Thota terrorist bastards are spy bastards, they don’t command me, I do whatever I like, because they use invisible spying drone they try to frame me“
This blog post is a general blog post on how centralized logging has been implemented, some of the tools used while keeping the costs low.
Having the ability to maintain logs is very important for software companies, even small startups. Centralized logging, monitoring, metrics and alerts are also important.
Log ingestion is done using FluentD. FluentD is installed on all the servers and even a Golden Base AMI has been created with FluentD installed.
Grafana Loki is used as the log ingestion server.
Grafana front-end for viewing logs from Loki.
FluentD has been configured to set different labels for different log sources, the output is written into Loki and into file output.
The output files would be zipped and uploaded into S3 with lifecycle policies. S3 buckets can be configured to be immutable i.e once a file is uploaded, can’t be deleted or re-written or modified until a specified period.
Loki has been configured with a smaller retention period. I wish Grafana Loki supported something like retaining time slices. More on the concept of time slices later in this blog post.
Loki can be configured for a longer retention period but unnecessary EBS storage costs. S3 Standard Infrequent Access or S3 Glacier Instant Retrieval are much cheaper for archival data. Based on your needs you can configure the system.
A new component in C# is being developed to ingest logs into Loki on a need basis. I will definitely post some sample code of the new component.
With the above configuration in place, once logs are written and within 6 minutes, the logs become immutable. Let’s say something happened, and was noticed within 1 day. I can immediately change the retention period of Loki and keep the log retention for longer period. If I saw some abnormality and if the logs are no longer available in Loki due to shorter retention period. The new component being developed would ingest the archived logs from S3 into Loki with the old timestamps. Under normal circumstances this wouldn’t be required, but there is no point in having archived logs that cannot be ingested and searched when required.
Some sample config elements for FluentD:
Code block for ingesting logs from CloudWatch:
I am ingesting CloudTrail logs, I would write a blog post or a video sometime later.
The above configs are pretty much self-explanatory. Using Loki, Grafana are also very easy. But most important thing, configure and use Grafana with a 3rd party login instead of just username and password. I can’t stress the importance of MFA and if possible use YubiKey Bio. Most other forms of MFA have vulnerabilities and are hackable considering the advanced capabilities of the R&AW / Mafia / Anonymous hackers group equipment.
Metrics:
I am using collectd, Carbon, Grafana cloud for metrics. i.e all the servers have collectd, collectd ingests metrics into Carbon, Carbon forwards these metrics into Grafana cloud. Based upon patterns, set threshold alerts. I am planning to ingest custom additional metrics. But that’s planned for later. Definitely when I get to this phase, I would write some blog posts.
Alerts:
Considering the R&AW / Mafia / Anonymous hackers threat (capabilities of the equipment) – the most damage can happen if they login into AWS Console / SSH into servers. I have wrote some custom code for a lambda that would parse cloudwatch logs looking for AWS console login pattern and sends an alert. This Lambda runs once every minute. The anonymous hackers / spies / R&AW / Mafia might screenshot my AWS account or even record video or even might show my screen in a live video but they can’t login because of biometric MFA authentication.
Similarly I have configured my servers to send an email alert as soon as a SSH login happens. I access my Linux servers from within AWS website using EC2 Instance Connect rather than direct SSH. In other words, if anyone wants to access my Linux servers, they have to first login into AWS console using YubiKey Bio – in other words, no one else can login as of now.
I can provide code samples for the above 2 activities in a later blog post.
TimeSlices:
Earlier, I mentioned about a concept – TimeSlices. I don’t need all logs forever, if I want a certain logstream during a certain period, retain those logs.
Similarly another nice to have feature would be the ability to configure different retention periods for different types of logs. For example, remove traces after x day, remove debug after y days, remove info after z day. Retain Warn, Error, Critical for a longer period.
I am hoping this blog post helps someone. If anyone needs any help with architecting, planning, designing, developing for horizontal and vertical scalability or want any help with centralized logging or enterprise search using Solr or ElasticSearch or want to reduce costs by rightsizing, please do contact me. I offer free consultation and we can agree on the work that needs to be performed and the pricing.
EFS stands for Elastic File System. EFS is a network filesystem where data can persistent and can be accessed by several different EC2 instances.
In pursuit of having my own crash-resistant, tamper-proof, immutable logs and any other future sensitive information I wanted to leverage EFS in my startup ALight Technology And Services Limited.
This article does not discuss EFS in-depth i.e throughput types, Standard vs One Zone etc.. This article is simply about how to mount and automatically mount.
Create the EFS in the region where you need. My current datacenter is in London, United Kingdom because my company is registered in London, United Kingdom (Once again my sincere respect and gratitude for the Government of United Kingdom)
In your EC2 security groups allow port 2049, attach the EC2’s security groups in the networking section of the EFS.
Recently, I have been writing on log management tools and techniques. Very recently, I am even evaluating Grafana Loki on-premise. I would write a review in few days regarding Grafana Loki. As of now from server hardware requirements, log volume ingestion standpoint Grafana seems excellent compared with ELK stack and GrayLog.
This blog post is a general blog post. For proper log management, we need different components.
Log ingestion client
Log ingestion server
Log Viewer
Some kind of long-term archiver that can restore certain logs on required basis (Optional)
Log Ingestion Client:
FluentD is the best log ingestion client for several reasons. Every log ingestion stack have their own log ingestion clients. ELK Stack has LogBeats, MetricBeats etc… GrayLog does not have a client of its own but supports log ingestion via Gelf / RSysLog etc… Grafana Loki has PromTail.
FluentD can collect logs from various sources and ingest into various destinations. Here is the best part – multiple destinations based on rules. For example certain logs can be ingested into Log servers and uploaded to S3. Very easy to configure and customize and there are plenty of plugins for sources, destinations and even customizing logs such as adding tags, extracting values etc… Here is a list of plugins.
FluentD can ingest into Grafana Loki, ELK stack, GrayLog and much more. If you use FluentD, if the target needs to be changed, its just a matter of configuration.
Log Ingestion Server:
ELK vs GrayLog vs Grafana Loki vs Seq and several others. As of now, I have evaluated ELK, GrayLog and Grafana Loki.
Log Viewer:
Grafana front end with Loki backend, GrayLog, Kibana frontend with ElasticSearch backend in ELK stack.
Long-Term Archiving:
ELK stack has lifecycle rules for backing up and restoring. GrayLog can be configured to close indexes and re-open on a necessary basis. Grafana Loki has retention and compactor settings. However, I have not figured out how to re-open compacted gz files on a necessity basis.
Apart from these, I am using Graphite for metrics. I do have plans for ingesting additional metrics. As of now, I am using the excellent hosted solution provided by Grafana. As of now, in the near-term I don’t have plans for self-hosting metrics. But Grafana front-end supports several data sources.
I am thinking of collecting certain extra metrics without overloading the application (might be an after-thought or might not be). I am collecting NGinx logs in json format. The URL, upstream connect, upstream response time are being logged. Now, by parsing these logs, the name of the ASP.Net MVC controller, name of the Action Method, the HTTP verb can be captured. Now, I can use these as metrics. I can very easily add metrics at the database layer in the application. With these metrics, I can easily identify bottlenecks, slow performing methods and even monitor average response times etc… and set alerts.
The next few days or weeks would be about the custom metric collection based on logs. You can expect few blog posts on some FluentD configuration, C# code etc… FluentD does have some plugins for collecting certain metrics but we will look into some C# code for parsing, sending metrics into Graphite.
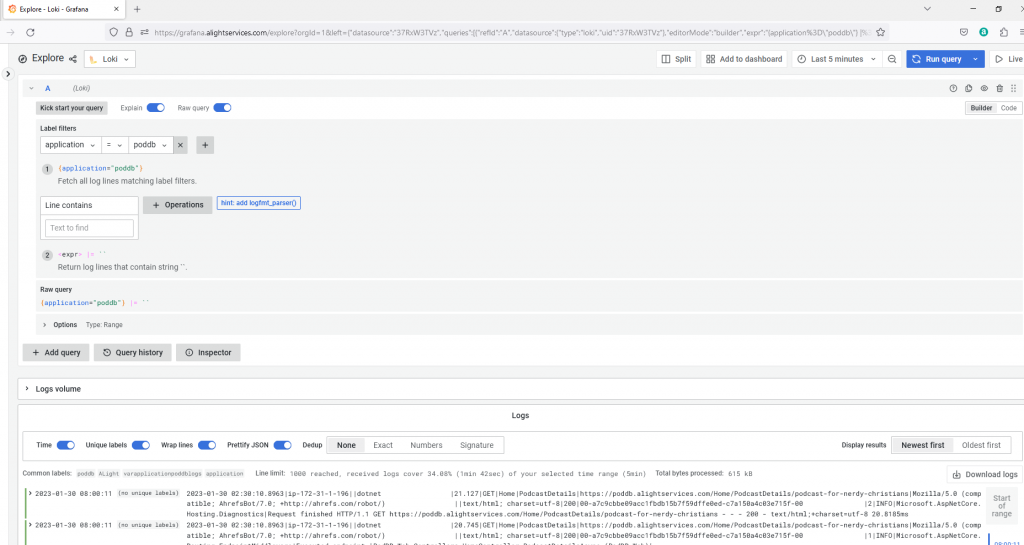
Here is a screenshot from the self-hosted Grafana front-end for Loki logs:
Grafana showing Loki logs for PodDB
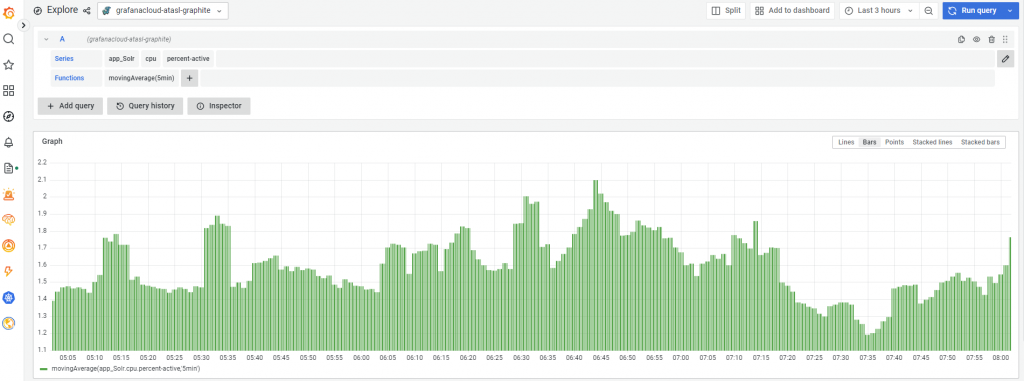
Here is a screenshot from Grafana.com hosted showing Graphite metrics
Graphite Solr Backend Server CPU usage
I am hoping this blog posts helps someone. Some C# code for working with Logs, Metrics and Graphite over the next few days / weeks.
And I have discussed about a possibility of capturing more information in logs only when needed such as in the case of errors or exceptions in the following blog post:
I am planning to use Gelf logging for easier compatibility reasons. Gelf logs can be ingested into pretty much every major centralized logging platforms such as: Kibana, GrayLog, Seq, Grafana. Some would require some intermediary software to accept Gelf formatted logs and some can directly ingest Gelf formatted logs. However, for various reasons, sometimes the logging server might not be available, specifically when the log ingestors are not in a cluster. Log files can be easily ingested into the above mentioned centralized logging agents using different sofware.
Based on the above use-case I wanted to use Gelf for directly logging into the centralized logging server and as a failover, I want to write the logs to a file that would get ingested at a later point by some other software.
Now, by combing the previous post example, we can achieve AspNetBuffering and ingest different levels of logs only when errors occur. The code samples should be very easy to understand.
In the above code we have wrapped Gelf logger, File logger inside a FallBackGroup logger. The FallBackGroup logger is wrapped inside a PostFilteringWrapper. The PostFilteringWrapper is wrapped inside a AspNetBufferingWrapper.
In the above code in the <rules> section we are sending all Debug and above logs to the AspNetBufferingWrapper.
Now AspNetBufferingWrapper buffers the log messages for an entire request, response cycle and sends the log messages to the PostFilteringWrapper.
The PostFilteringWrapper sees if there are any Warnings or above loglevel, if yes sends all the messages that have Debug and above loglevels. Else sends Info and above messages. The target of PostFilteringWrapper is the FallbackGroup logger which receives these messages.
The FallBackGroup logger attempts to use the Gelf logger, if the Gelf logger is unable to process the messages, the logs are sent to the File logger.
And I have discussed about a possibility of capturing more information in logs only when needed such as in the case of errors or exceptions in the following blog post:
The above configuration by default logs Info and above logs, but if there is a Warn or higher, logs debug or higher. For this to work properly obviously this logger has to receive Debug messages otherwise there is no point in using this logger.
Now combing these two loggers, here is an example:
I have evaluated few different centralized logging tools, specifically the following:
Grafana Loki
Kibana
Graylog
Seq
In the short-term, I am using Graylog, but in the next few years, I might choose a different option.
The key features I have been looking for are:
Lower hardware requirements – for a small startup without any revenue yet, I didn’t want to spend too much.
Customizable retention period of logs
Being able to backup logs to some cheaper storage such as S3 rather than having 100’s of GB on EBS volumes.
Easily able to restore a smaller portion of logs for a certain period and be able to search.
Being able to ingest various types of logs
Let me explain my personal requirements clearly.
I want to ingest all the logs from all possible sources i.e system logs, software logs such as web server, mysql audit logs, custom application logs. Currently my applications and servers are generating approximately 800Mb of logs per day. That would be about 25Gb per month and 300Gb per year. I want to retain logs for a longer period in archives for various reasons. I currently don’t have any products that need to meet compliance requirements. I arbitrarily choose 400 days worth of log retention and the logs need to be immutable. Once the logs are ingested, the logs need to be stored for 400 days and should not be modified. The reason being in the future if I need to meet compliance requirements, it would be easy to change the retention period and the integrity of the logs can be verified.
I have read about but have not evaluated the following yet:
Self-Hosted Seq
Self-Hosted Grafana Loki
Given the above I will tell you the advantages and disadvantages of each solution.
Grafana Loki hosted:
Grafana has a very generous free tier with 50Gb log ingestion and 14 days retention. The paid customized plans pricing was not clear. Considering the logs are hosted by a 3rd party, I would hope they would introduce some additional security measures such as allowing log ingestion from only certain IP’s etc… Even if the API keys are stolen or spied upon, the hackers cannot pollute the log data.
Self-Hosted ELK stack:
This is one very great solution but the setup and versions compatibility is very problematic. Self-Hosted ELK stack is a little heavy on resources. But definitely worth for SME’s who have the budget for the required hardware and few Server Admin professionals on team. As of now, because of the R&AW harassment, impersonation, I don’t know when I would launch commercial products. And these are recurring expenses, not one time expenses, so I am trying to set myself for success with smaller monthly server expenses. I wish these psycho human rights violators get arrested. There are ways to export backups into S3, almost a perfect solution
GrayLog OpenSource:
GrayLog is a bit heavy on system resources but requires lesser resources compared with ELK stack. Indexes can be closed but backing up and restoring are not directly part of the application. Probably part of the GrayLog paid version.
AWS CloudWatch:
AWS Cloudwatch is perfect if there is a need for compliance with retention policies and immutability. CloudWatch logs can be exported into S3 buckets. S3 buckets can be configured to be immutable for compliance reasons and S3 lifecycle policies can be defined for removal of data etc… But querying data is a little problematic compared with the ease of other solutions.
Seq:
Seq has a free version, seemed to be light-weight. Very easy to write extensions using C# (My primary development language). There is no direct plugin for for exporting data into S3 but a customizable plugin might be possible. There are plugins for writing into an Archive file. The Archive file can be exported to S3 periodically. Trying on localhost is very easy – pull a docker image and run the docker image. No complicated setup.
Self-hosted Grafana Loki:
I think pretty much all the capabilities of hosted Grafana Loki might be possible. However, I haven’t tried yet.
In all the above solutions, logs could be tampered by hackers except with AWS Cloudwatch. Once ingested, the logs stay there un-tampered. If Admin’s account gets hacked, the retention period can be changed or log streams might be deleted, but cannot be tampered.
As of now, I have not yet found the perfect solution for my requirements, but I am hoping this blog post helps some people in deciding between various different centralized logging solutions based upon your own requirements.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category .
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.