This blog post is a general blog post on how centralized logging has been implemented, some of the tools used while keeping the costs low.
Having the ability to maintain logs is very important for software companies, even small startups. Centralized logging, monitoring, metrics and alerts are also important.
Log ingestion is done using FluentD. FluentD is installed on all the servers and even a Golden Base AMI has been created with FluentD installed.
Grafana Loki is used as the log ingestion server.
Grafana front-end for viewing logs from Loki.
FluentD has been configured to set different labels for different log sources, the output is written into Loki and into file output.
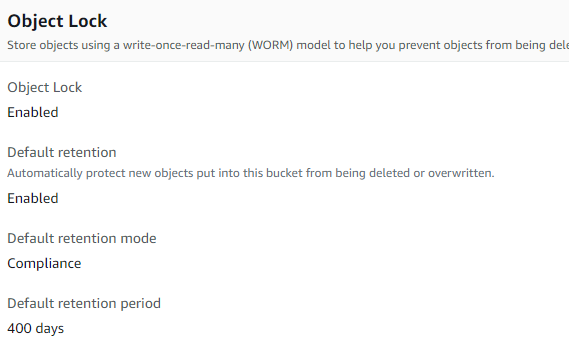
The output files would be zipped and uploaded into S3 with lifecycle policies. S3 buckets can be configured to be immutable i.e once a file is uploaded, can’t be deleted or re-written or modified until a specified period.
Loki has been configured with a smaller retention period. I wish Grafana Loki supported something like retaining time slices. More on the concept of time slices later in this blog post.
Loki can be configured for a longer retention period but unnecessary EBS storage costs. S3 Standard Infrequent Access or S3 Glacier Instant Retrieval are much cheaper for archival data. Based on your needs you can configure the system.
A new component in C# is being developed to ingest logs into Loki on a need basis. I will definitely post some sample code of the new component.
With the above configuration in place, once logs are written and within 6 minutes, the logs become immutable. Let’s say something happened, and was noticed within 1 day. I can immediately change the retention period of Loki and keep the log retention for longer period. If I saw some abnormality and if the logs are no longer available in Loki due to shorter retention period. The new component being developed would ingest the archived logs from S3 into Loki with the old timestamps. Under normal circumstances this wouldn’t be required, but there is no point in having archived logs that cannot be ingested and searched when required.
Some sample config elements for FluentD:
Code block for ingesting logs from CloudWatch:
I am ingesting CloudTrail logs, I would write a blog post or a video sometime later.
<source>
@id cloudwatch_logs
@type cloudwatch_logs
tag cloudwatch.cloudtrail
log_group_name <LOG_GROUP_NAME>
add_log_group_name false
use_log_group_name_prefix true
log_stream_name <LOG_STREAM_PREFIX>
use_log_stream_name_prefix true
region <AWS-REGION>
include_metadata true
<parse>
@type json
</parse>
<storage>
@type local
path /var/log/td-agent/cloudwatch_cloudtrail.json
</storage>
</source>Sample for log files:
<source>
@type tail
@id grafana
path /var/log/grafana/*.log
pos_file /var/log/td-agent/grafana.pos
tag software.grafana
refresh_interval 5
<parse>
@type none
</parse>
read_from_head true
pos_file_compaction_interval 1h
</sourceSample filters for adding additional labels:
<filter **>
@type record_transformer
<record>
tag_name ${tag}
td_host GrafanaLoki
</record>
</filter>
<filter cloudwatch.**>
@type record_transformer
<record>
group cloud
subgroup cloudwatch
</record>
</filter>Sample for outputting into files, archiving, ingesting into loki
<match **>
@type copy
@id copy
<store>
@id loki
@type loki
url "http://grafanaloki:3100"
extra_labels {"env":"Grafana", "host":"Grafana"}
flush_interval 1s
flush_at_shutdown true
buffer_chunk_limit 1m
<label>
tag_name
td_host
group
subgroup
level_three
</label>
</store>
<store>
@id file
@type file
path /var/log/fluentd/grafana_1/${tag}/file.GrafanaLoki.%Y-%m-%d_%H:%M:00
append true
<buffer tag, time>
timekey 5m
timekey_use_utc true
timekey_wait 1m
</buffer>
</store>
</match>The above configs are pretty much self-explanatory. Using Loki, Grafana are also very easy. But most important thing, configure and use Grafana with a 3rd party login instead of just username and password. I can’t stress the importance of MFA and if possible use YubiKey Bio. Most other forms of MFA have vulnerabilities and are hackable considering the advanced capabilities of the R&AW / Mafia / Anonymous hackers group equipment.
Metrics:
I am using collectd, Carbon, Grafana cloud for metrics. i.e all the servers have collectd, collectd ingests metrics into Carbon, Carbon forwards these metrics into Grafana cloud. Based upon patterns, set threshold alerts. I am planning to ingest custom additional metrics. But that’s planned for later. Definitely when I get to this phase, I would write some blog posts.
Alerts:
Considering the R&AW / Mafia / Anonymous hackers threat (capabilities of the equipment) – the most damage can happen if they login into AWS Console / SSH into servers. I have wrote some custom code for a lambda that would parse cloudwatch logs looking for AWS console login pattern and sends an alert. This Lambda runs once every minute. The anonymous hackers / spies / R&AW / Mafia might screenshot my AWS account or even record video or even might show my screen in a live video but they can’t login because of biometric MFA authentication.
Similarly I have configured my servers to send an email alert as soon as a SSH login happens. I access my Linux servers from within AWS website using EC2 Instance Connect rather than direct SSH. In other words, if anyone wants to access my Linux servers, they have to first login into AWS console using YubiKey Bio – in other words, no one else can login as of now.
I can provide code samples for the above 2 activities in a later blog post.
TimeSlices:
Earlier, I mentioned about a concept – TimeSlices. I don’t need all logs forever, if I want a certain logstream during a certain period, retain those logs.
Similarly another nice to have feature would be the ability to configure different retention periods for different types of logs. For example, remove traces after x day, remove debug after y days, remove info after z day. Retain Warn, Error, Critical for a longer period.
I am hoping this blog post helps someone. If anyone needs any help with architecting, planning, designing, developing for horizontal and vertical scalability or want any help with centralized logging or enterprise search using Solr or ElasticSearch or want to reduce costs by rightsizing, please do contact me. I offer free consultation and we can agree on the work that needs to be performed and the pricing.
–
Mr. Kanti Kalyan Arumilli

B.Tech, M.B.A
Founder & CEO, Lead Full-Stack .Net developer
ALight Technology And Services Limited
Phone / SMS / WhatsApp on the following 3 numbers:
+91-789-362-6688, +1-480-347-6849, +44-07718-273-964
kantikalyan@gmail.com, kantikalyan@outlook.com, admin@alightservices.com, kantikalyan.arumilli@alightservices.com, KArumilli2020@student.hult.edu, KantiKArumilli@outlook.com and 3 more rarely used email addresses – hardly once or twice a year.